A deep dive into unicode and string matching -I

"The ecology of the distributed high-tech workplace, home, or school is profoundly impacted by the relatively unstudied infrastructure that permeates all its functions" - Susan Leigh Star
Representing, processing, sending and receiving text (also known as strings in computer-speak) is one of the most common things computers do. Text representation and manipulation in a broad sense, has a quasi infrastructural1 quality to it, we all use it in one form or another and it generally works really well - so well in fact that we often don't pay attention to how it all works behind the scenes.
As software developers it is key to have a good grasp of how computers represent text, especially as in certain application domains even supposedly "simple" operations like assessing if two strings are the same has a surprising depth to it. After all should the string "Bruno Felix" be considered to be the same as the string "Bruno Félix" (note the acute "e" on the last name)? The answer of course is: "it depends".
But let's start from the beginning, in this series I am going to explore the Unicode standard, going a bit beyond the bare minimum every developer needs to know, and into some aspects that are not often not widely talked about, in particular about how characters with diacritics are represented, and how this impacts common operations like string comparisons and ordering.
The briefest history of text representations ever
There is already a lot of good material out there about how computers represent text2 which I highly recommend. For the sake of this article I'm going to speed run through the history of how computers represent text, in order to be able to dive in more detail at the internals of Unicode.
So in a very abbreviated manner: computers work with numbers, so the obvious thing to do to represent text is to assign a number to each letter. This is basically true to this day. Since the initial developments in digital computing were done in the USA and the UK, English became (and still is) the lingua franca of computing. It was straightforward to come up with a mapping between every letter in the English alphabet, digits, common punctuation marks plus some control characters, and a number. This mapping is called an encoding, and probably the oldest encoding you will find out there in the wild is ASCII, which is able to do exactly this for the English alphabet - and do so using only in 7 bits.
We can actually see this in action if we save the string Hello in ASCII in a file and dump its hexadecimal content.
$ hexdump -C hello-ascii.txt
00000000 48 65 6c 6c 6f |Hello|
00000005
Of course this was far from perfect, especially if you're not an English speaker. What about all the other languages out there in the world? And to do that in a way that maintains retro compatibility with ASCII?
Since computers work in multiples of 2 thus 8 bit bytes, this means ASCII leaves one bit available, the ASCII 7 bit encoding is quite easy to extend by adding an additional bit (nice as it maintains retro compatibility), doubling the number of characters available and still making everything fit in a single byte. Amazing! This is actually what vendors did, and this eventually got standardized in encodings like ISO 8859-1. Of course 255 characters is not enough to fit every character for every writing system out there, so the way this was initially approached was to have several "code pages", that essentially map the 1 byte number to different alphabets (e.g. the Latin alphabet has one code page, the Greek alphabet had another).A consequence of this is that in order to make sense of a piece of text one needs additional meta-information about which code page to use: after all character 233 will change depending on the code page (and of course it still doesn't work for alphabets with thousands of characters)
If we have the string Félix written in ISO-8859-1 (Latin) and read the same string in ISO-8859-7 (Greek) we get Fιlix, despite the fact that the bytes are exactly the same!
$ hexdump -C felix-code-page-confusion.txt
00000000 46 e9 6c 69 78 |F.lix|
00000005
A brief intro to Unicode and character encodings
The example above is not only an interoperability nightmare, but it still doesn't cover all languages in use so it's not a sustainable solution to the issue of text representation. Unicode3 tries to address these issues by starting from a simple idea: each character is assigned its own number, that is é and ι will be assigned different numbers (code points in Unicode terminology). Code points are typically represented by U+ followed by the hexadecimal encoded value of the character, so for instance é is represented as U+00E9 and ι is
represented as U+03B9. The code points are also selected in such a way that retro compatibility is maintained with ISO-8859-1, and ASCII.
Currently Unicode has defined code points for more than 149186 characters (AKA code points), and this covers not only languages that are in active use today, but also historical (e.g. Cuneiform) or fictional languages (e.g. Tengwar4). Although it is important to note that most characters in use are encoded by the first 65,536 code points. In total Unicode allows the definition of up to 1114112 code points characters, so it is quite future-proof.
An important thing to note is that code points don't specify anything at all about how they are converted to actual bytes in memory or on a disk - they are abstract ideas. This is one of the key things to keep in mind when thinking about Unicode, there is by design a clear difference between identifying a character, representing it in a way that a computer can process it and rendering a glyph on a screen.
The good thing about standards is that you get to choose - Unknown
So if code points are notional, abstract ideas, how can computers make use of them? This is where encodings come into the picture. Unicode Standard offers several different options to represent characters: a 32-bit form (UTF-32), a 16-bit form (UTF-16), and an 8-bit form (UTF-8). The key idea here is that a code point (which is an integer at the end of the day) is represented by one or mode code units. UTF-32/16/8 offer different base sizes for these code units.
When working with UTF-32 and UTF-16, the endianness,that is the order of the most significant or least significant byte needs to be considered.
UTF-32 provides fixed length code units, making it simple to process. This comes at the cost of increased memory or disk storage space for characters.
$ hexdump -C hello-utf32-little-endian.txt
00000000 48 00 00 00 65 00 00 00 6c 00 00 00 6c 00 00 00 6f 00 00 00 |H...e...l...l...o...|
0000000a
$ hexdump -C hello-utf32-big-endian.txt
00000000 00 00 00 48 00 00 00 65 00 00 00 6c 00 00 00 6c 00 00 00 6f |...H...e...l...l...o|
0000000a
UTF-16 provides a balance between processing efficiency and storage requirements. This is because all the commonly used characters fit into a single 16-bit code unit, but it is important to keep in mind that this is still a variable length encoding (a code-point may span one or two code units). Fun fact: the JVM and the CLR use UTF-16 strings internally.
$ hexdump -C hello-utf16-little-endian.txt
00000000 48 00 65 00 6c 00 6c 00 6f 00 |H.e.l.l.o.|
0000000a
$ hexdump -C hello-utf16-big-endian.txt
00000000 00 48 00 65 00 6c 00 6c 00 6f |.H.e.l.l.o|
0000000a
Finally, UTF-8 is a byte oriented variable length encoding (so be careful with the assumption that each character is a byte, that is not what the 8 in UTF-8 means!). Since it is byte oriented, and the code points have been carefully chosen, this encoding is retro compatible with ASCII (note the example below). On the other hand a code point may be anywhere from 1 to 4 8 bit code units long, so processing will be more complex.
$ hexdump -C hello-utf8.txt
00000000 48 65 6c 6c 6f |Hello|
00000005
This essentially allows programmers to trade off simplicity in processing with resources (memory or storage space) and retro-compatibility requirements according to the specific needs of their application. The following picture (directly from Chapter 25 of the Unicode Standard may further clarify things):
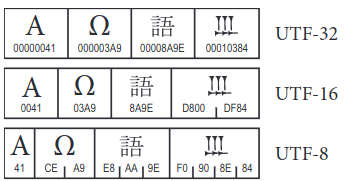
Hopefully this brief intro provides a good foundation as to why Unicode has become the de-facto way to represent text, and the key difference between code points and encodings. This serves as a stepping stone to further explore the Unicode Standard, and in the next post in this series I will dive a bit deeper into how code points are structured, the types of characters that exist and how they are combined and can be normalized.